

大家好,今天小编关注到一个比较有意思的话题,就是关于kafka数据保存多久的问题,于是小编就整理了4个相关介绍的解答,让我们一起看看吧。
kafka扩容是否影响下发数据?
Kafka扩容不会影响下发数据。Kafka通过分区机制将数据分散储存于不同的节点上,当扩容时只需添加新的节点并重新分配分区即可,已存在的节点不会停止服务或删除数据,因此不会影响已经下发的数据。扩容后,Kafka可以通过更多的节点提供更高的吞吐量和更好的性能,进一步满足业务需求。
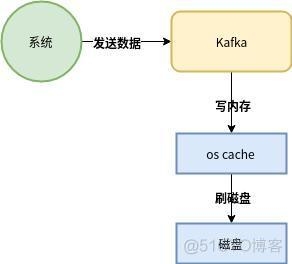
spark怎么处理kafka中的json的数据?
构造函数为KafkaUtils.createDstream(ssc, [zk], [consumer group id], [per-topic,partitions] ) 使用了receivers来接收数据,利用的是Kafka高层次的消费者api,对于所有的receivers接收到的数据将会保存在spark executors中,然后通过Spark Streaming启动job来处理这些数据,默认会丢失,可启用WAL日志,该日志存储在HDFS上
kafka偏移量如何维护?
kafka消息的偏移量维护是用好kafka的关键,维护偏移量可以避免重复消费和消息遗漏,从而确保消息至少消费一次。
消息的存放位置由主题(topic),分片(partitions),偏移(offsets)共同决定,消息的消费位置与消费者和分组有关。

kafka会记录2个偏移,一个是消费偏移(为A),一个是消息存储的最早偏移(为B)。假如A>B 消息会被正常消费。如果A<B同时A超出数据过期删除时间,这样就会有问题,可以适当调整kafka的数据过期删除时间和保留数据大大小。
可能还有一种情况需要注意,有一个消息总是消费失败问题。
kafkaitemreader怎么使用?
您需要为此使用持久性作业库,并将KafkaItemReader配置为保存其状态.状态包含在分配给读取器的每个分区的偏移量中,并将保存在块边界(也称为每个事务)中

到此,以上就是小编对于kafka数据保存时间的问题就介绍到这了,希望介绍的4点解答对大家有用。
")
")
")
")



